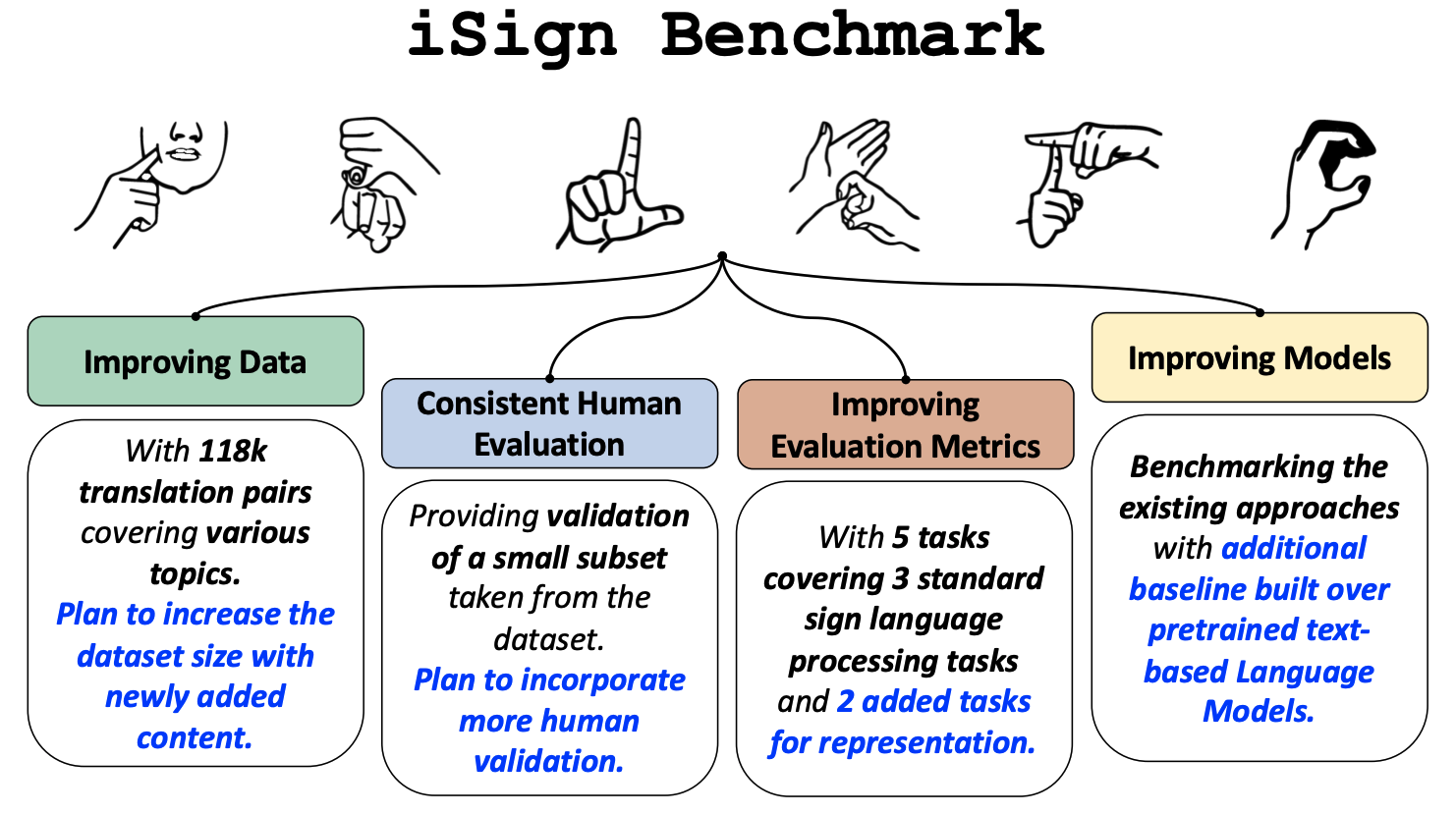
ISL-to-English is a standard task of machine translation, with ISL-video as input and corresponding English translations as predictions. Dataset Links: ISLVideo-to-English Translation b) ISLPose-to-English Translation
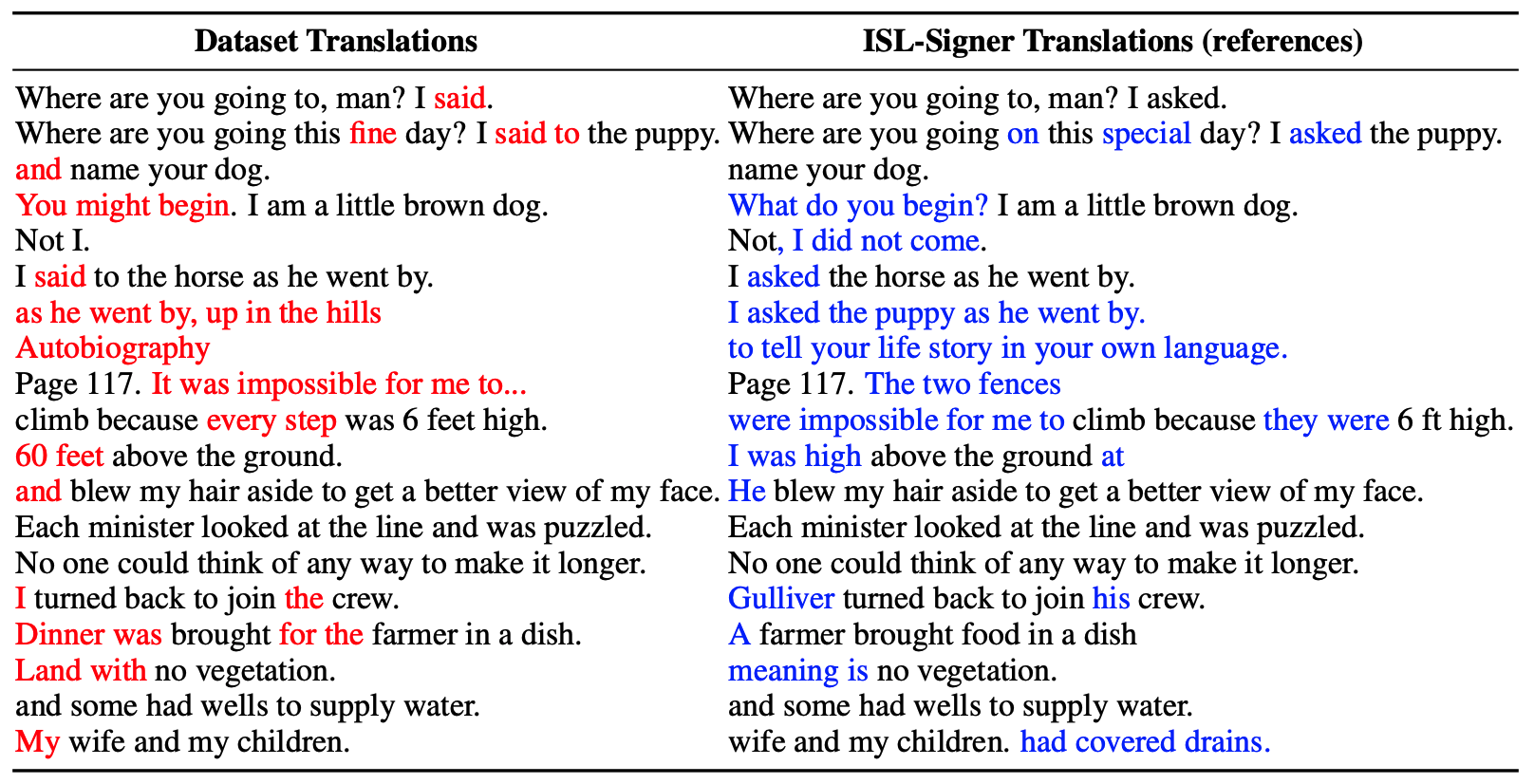
English Translation (reference): "However in India there is a huge demand for cheap phones."
English Input: "has not recorded a single COVID infection till now."
We use the dataset provided by CISLR [EMNLP 2022]. The dataset can be accessed using this link .
For this task we use query-candidate pairs of ISL videos, below is the example of ISL word video and ISL sentence video. The complete dataset for word-sentence pairs can be found here.
Word (query): "premises"
Example Sentence (candidate): "The company is moving to new premises next month."
For this task we use query-candidate pairs of ISL videos, below is the example of ISL word video and ISL video explaining the meaning of the respective word. The complete dataset for query-candidate pairs can be found here.
Word (query): "immediate"
Description (candidate): "happening or done without delay or very soon after something else"
@inproceedings{iSign-2024,
title = "i{S}ign: A Benchmark for {I}ndian {S}ign {L}anguage Processing",
author = "Joshi, Abhinav and
Mohanty, Romit and
Kanakanti, Mounika and
Mangla, Andesha and
Choudhary, Sudeep and
Barbate, Monali and
Modi, Ashutosh",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.643",
doi = "10.18653/v1/2024.findings-acl.643",
pages = "10827--10844",
abstract = "Indian Sign Language has limited resources for developing machine learning and data-driven approaches for automated language processing. Though text/audio-based language processing techniques have shown colossal research interest and tremendous improvements in the last few years, Sign Languages still need to catch up due to the need for more resources. To bridge this gap, in this work, we propose \textbf{iSign}: a benchmark for Indian Sign Language (ISL) Processing. We make three primary contributions to this work. First, we release one of the largest ISL-English datasets with more than video-sentence/phrase pairs. To the best of our knowledge, it is the largest sign language dataset available for ISL. Second, we propose multiple NLP-specific tasks (including SignVideo2Text, SignPose2Text, Text2Pose, Word Prediction, and Sign Semantics) and benchmark them with the baseline models for easier access to the research community. Third, we provide detailed insights into the proposed benchmarks with a few linguistic insights into the working of ISL. We streamline the evaluation of Sign Language processing, addressing the gaps in the NLP research community for Sign Languages. We release the dataset, tasks and models via the following website: https://exploration-lab.github.io/iSign/",
}
}@inproceedings{isltranslate-2023,
title = "{ISLT}ranslate: Dataset for Translating {I}ndian {S}ign {L}anguage",
author = "Joshi, Abhinav and
Agrawal, Susmit and
Modi, Ashutosh",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.665",
doi = "10.18653/v1/2023.findings-acl.665",
pages = "10466--10475",
abstract = "Sign languages are the primary means of communication for many hard-of-hearing people worldwide. Recently, to bridge the communication gap between the hard-of-hearing community and the rest of the population, several sign language translation datasets have been proposed to enable the development of statistical sign language translation systems. However, there is a dearth of sign language resources for the Indian sign language. This resource paper introduces ISLTranslate, a translation dataset for continuous Indian Sign Language (ISL) consisting of 31k ISL-English sentence/phrase pairs. To the best of our knowledge, it is the largest translation dataset for continuous Indian Sign Language. We provide a detailed analysis of the dataset. To validate the performance of existing end-to-end Sign language to spoken language translation systems, we benchmark the created dataset with a transformer-based model for ISL translation.",
}
}@inproceedings{cislr-2022,
title = "{CISLR}: Corpus for {I}ndian {S}ign {L}anguage Recognition",
author = "Joshi, Abhinav and
Bhat, Ashwani and
S, Pradeep and
Gole, Priya and
Gupta, Shashwat and
Agarwal, Shreyansh and
Modi, Ashutosh",
editor = "Goldberg, Yoav and
Kozareva, Zornitsa and
Zhang, Yue",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.707",
doi = "10.18653/v1/2022.emnlp-main.707",
pages = "10357--10366",
abstract = "Indian Sign Language, though used by a diverse community, still lacks well-annotated resources for developing systems that would enable sign language processing. In recent years researchers have actively worked for sign languages like American Sign Languages, however, Indian Sign language is still far from data-driven tasks like machine translation. To address this gap, in this paper, we introduce a new dataset CISLR (Corpus for Indian Sign Language Recognition) for word-level recognition in Indian Sign Language using videos. The corpus has a large vocabulary of around 4700 words covering different topics and domains. Further, we propose a baseline model for word recognition from sign language videos. To handle the low resource problem in the Indian Sign Language, the proposed model consists of a prototype-based one-shot learner that leverages resource rich American Sign Language to learn generalized features for improving predictions in Indian Sign Language. Our experiments show that gesture features learned in another sign language can help perform one-shot predictions in CISLR.",
}
}